



We just lately began a small mission to scrub up how elements of our methods talk behind the scenes at Buffer.
Some fast context: we use one thing referred to as SQS (Amazon Easy Queue Service. These queues act like ready rooms for duties. One a part of our system drops off a message, and one other picks it up later. Consider it like leaving a word for a coworker: “Hey, if you get an opportunity, course of this knowledge.” The system that sends the word does not have to attend round for a response.
Our mission was to carry out routine upkeep: replace the instruments we use to check queues domestically and clear up their configuration.
However whereas we had been mapping out what queues we truly use, we discovered one thing we did not anticipate: seven totally different background processes (or cron jobs, that are scheduled duties that run mechanically) and employees that had been operating silently for as much as 5 years. All of them doing completely nothing helpful.
Here is why that issues, how we discovered them, and what we did about it.
Why this issues greater than you’d assume
Sure, operating pointless infrastructure prices cash. I did a fast calculation and for a kind of employees, we might have paid ~$360-600 over 5 years. This can be a modest quantity within the grand scheme of our funds, however positively pure waste for a course of that does nothing.
Nevertheless, after going by way of this cleanup, I would argue the monetary value is definitely the smallest a part of the issue.
Each time a brand new engineer joins the workforce and explores our methods, they encounter these mysterious processes. “What does this employee do?” turns into a query that eats up onboarding time and creates uncertainty. We have all been there — observing a bit of code, afraid to the touch it as a result of perhaps it is doing one thing necessary.
Even “forgotten” infrastructure sometimes wants consideration. Safety updates, dependency bumps, compatibility fixes when one thing else modifications. This led to our workforce spending upkeep cycles on code paths that served no function.
And over time, the institutional information fades. Was this important? Was it a brief repair that turned everlasting? The one that created it left the corporate years in the past, and the context left with them.
How does this even occur?
It is simple to level fingers, however the reality is that this occurs naturally in any long-lived system.
A function will get deprecated, however the background job that supported it retains operating. Somebody spins up a employee “quickly” to deal with a migration, and it by no means will get torn down. A scheduled job turns into redundant after an architectural change, however no person thinks to examine.
We used to ship birthday celebration emails at Buffer. To do that, we ran a scheduled job that checked your complete database for birthdays matching the present date and despatched prospects a customized electronic mail. Throughout a refactor in 2020, we switched our transactional electronic mail instrument however forgot to take away this employee—it saved operating for 5 extra years.
None of those are failures of people — they’re failures of course of. With out intentional cleanup constructed into how we work, entropy wins.
How our structure helped us discover it
Like many corporations, Buffer embraced the microservices motion (a preferred method the place corporations cut up their code into many small, impartial providers) years in the past.
We cut up our monolith into separate providers, every with its personal repository, deployment pipeline, and infrastructure. On the time, it made sense: every service may very well be deployed by itself, with clear boundaries between groups.
However through the years, we discovered the overhead of managing dozens of repositories outweighed the advantages for a workforce our measurement. So we consolidated right into a multi-service single repository. The providers nonetheless exist as logical boundaries, however they dwell collectively in a single place.
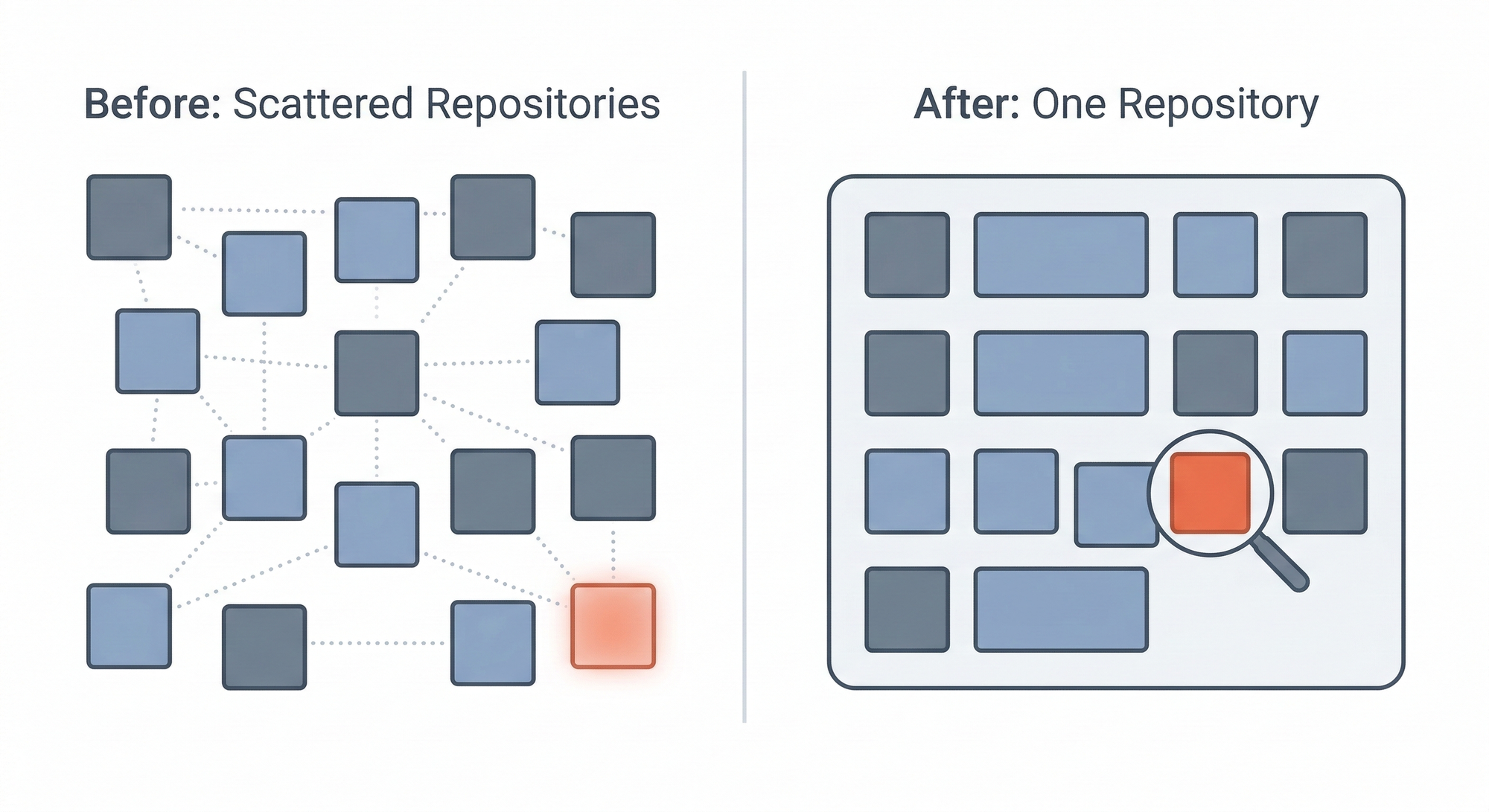
This turned out to be what made discovery potential.
Within the microservices world, every repository is its personal island. A forgotten employee in a single repo may by no means be observed by engineers working in one other. There isn’t any single place to seek for queue names, no unified view of what is operating the place.
With the whole lot in a single repository, we may lastly see the complete image. We may hint each queue to its shoppers and producers. We may spot queues with producers however no shoppers. We may discover employees referencing queues that not existed.
The consolidation wasn’t designed to assist us discover zombie infrastructure — but it surely made that discovery virtually inevitable.
What we truly did
As soon as we recognized the orphaned processes, we needed to determine what to do with them. Here is how we approached it.
First, we traced every one to its origin. We dug by way of git historical past and previous documentation to know why every employee was created within the first place. Normally, the unique function was clear: a one-time knowledge migration, a function that received sundown, a brief workaround that outlived its usefulness.
Then we confirmed they had been really unused. Earlier than eradicating something, we added logging to confirm these processes weren’t quietly doing one thing necessary we would missed. We monitored for a couple of days to ensure they weren’t referred to as in any respect, and we eliminated them incrementally. We did not delete the whole lot directly. We eliminated processes one after the other, looking forward to any sudden unwanted effects. (Fortunately, there weren’t any.)
Lastly, we documented what we discovered. We added notes to our inner docs about what every course of had initially accomplished and why it was eliminated, so future engineers would not marvel if one thing necessary went lacking.
What modified after clear up
We’re nonetheless early in measuring the complete affect, however here is what we have seen to this point.
Our infrastructure stock is now correct. When somebody asks, “What employees will we run?” we are able to truly reply that query with confidence.
Onboarding conversations have gotten less complicated, too. New engineers aren’t stumbling throughout mysterious processes and questioning in the event that they’re lacking context. The codebase displays what we truly do, not what we did 5 years in the past.
Deal with refactors as archaeology and prevention
My greatest takeaway from this mission: each vital refactor is a chance for archaeology.
Once you’re deep in a system, actually understanding how the items join, you are within the good place to query what’s nonetheless wanted. That queue from some previous mission? The employee somebody created for a one-time knowledge migration? The scheduled job that references a function you’ve got by no means heard of? They may nonetheless be operating.
Here is what we’re constructing into our course of going ahead:
- Throughout any refactor, ask: what else touches this technique that we have not checked out shortly?
- When deprecating a function, hint all of it the best way to its background processes, not simply the user-facing code.
- When somebody leaves the workforce, doc what they had been answerable for, particularly the stuff that runs within the background.
We nonetheless have older elements of our codebase that have not been migrated to the only repository but. As we proceed consolidating, we’re assured we’ll discover extra of those hidden relics. However now we’re set as much as catch them and forestall new ones from forming.
When all of your code lives in a single place, orphaned infrastructure has nowhere to cover.